The Equation That Made Words Do Math
A Google researcher discovered that neural networks could learn word meanings so precisely that 'King minus Man plus Woman equals Queen' — and it actually worked.
Aelu013 / CC BY-SA 4.0
You shall know a word by the company it keeps.
— J.R. Firth
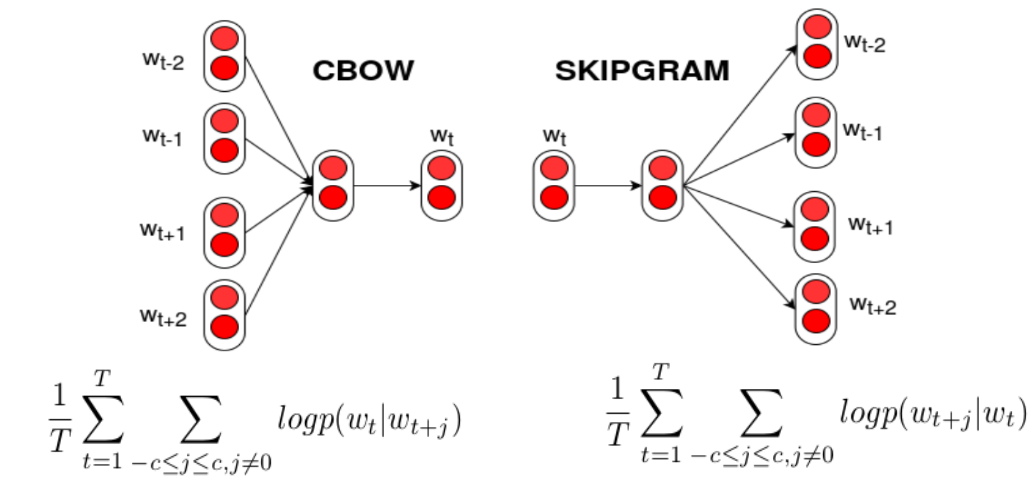
In 2013, a groundbreaking technique called Word2Vec emerged, revolutionizing the way machines understand language by converting words into numerical vectors that capture their semantic meaning.
What happened: In 2013, Tomáš Mikolov, Kai Chen, Greg Corrado, Ilya Sutskever, and Jeffrey Dean at Google introduced Word2Vec, a method for generating vector representations of words based on their context in large text corpora. This technique allowed for the detection of synonymous words and the suggestion of additional words for incomplete sentences, marking a significant advancement in natural language processing. Word2vec - Wikipedia
Why it matters: Word2Vec demonstrated that language could be compressed into dense vector spaces where arithmetic operations on word embeddings captured semantic relationships. This foundational work became a cornerstone for nearly all modern NLP systems and paved the way for the representational learning revolution that led directly to transformers and large language models. Efficient Estimation of Word Representations in Vector Space (original paper)
Further reading:
Why This Mattered
Word2Vec demonstrated that language could be compressed into dense vector spaces where arithmetic on word embeddings captured semantic relationships. It became a foundational building block for nearly all modern NLP systems and helped ignite the representational learning revolution that led directly to transformers and large language models.