The Architecture That Ate AI
A team at Google introduced the Transformer, a deceptively simple attention-based model that would become the foundation of virtually every major AI breakthrough that followed.
Xuemin Zhao, Ran Duan, Shaowen Yao / CC BY 4.0
We wanted to get rid of recurrence entirely… the key insight was that attention alone is sufficient.
— Ashish Vaswani
The Transformer: The Architecture That Ate AI
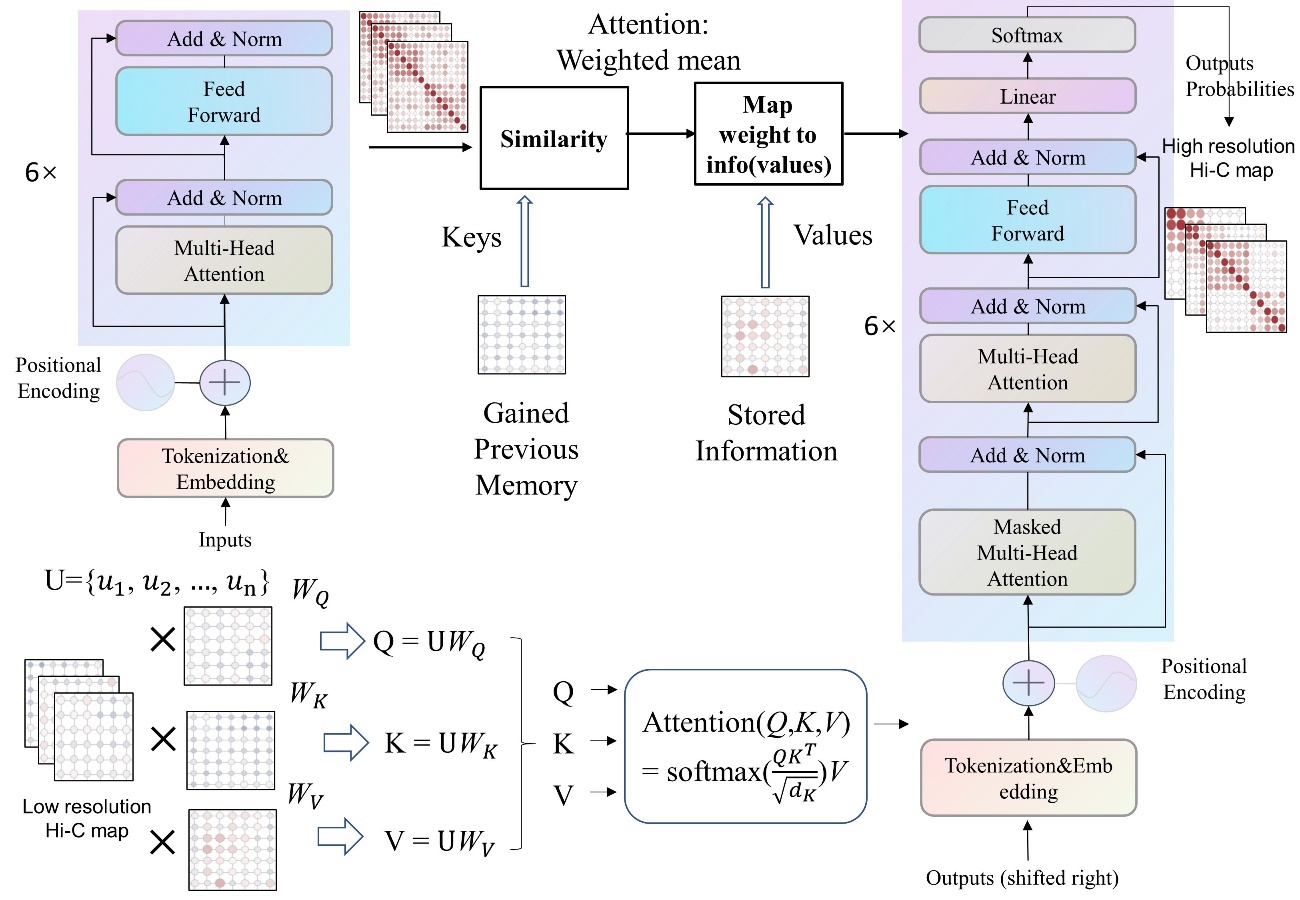
In 2017, the Transformer architecture revolutionized artificial intelligence by replacing recurrent and convolutional neural networks with pure self-attention mechanisms, fundamentally changing how AI processes and understands language.
What happened: In 2017, Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin introduced the Transformer, an artificial neural network architecture based on the multi-head attention mechanism. This breakthrough allowed for massive parallelization during training, significantly reducing the time required compared to earlier recurrent neural architectures. Link to paper.
Why it matters: The Transformer’s ability to handle sequential data without the need for recurrent units made it the backbone of numerous foundation models, including GPT, BERT, AlphaFold 2, and DALL-E. Its impact on the field of AI is profound, as it enabled the development of large language models that can generate human-like responses and understand complex language patterns.
Further reading:
Why This Mattered
The Transformer replaced recurrent and convolutional architectures with pure self-attention, enabling massive parallelization during training. It became the backbone of GPT, BERT, AlphaFold 2, DALL-E, and nearly every foundation model, making it arguably the single most consequential architecture in modern AI.